-
개인 공부 목적의 포스팅입니다. 잘못된 정보가 있다면 댓글 남겨주시면 수정하도록 하겠습니다.
감사합니다.👀 미리 보기


💡 주제 설명
Attention 매커니즘 중, additive한 접근법 중 하나인 Bahdanau Attention을 공부하고 진행한 실습
📌 배경
attention을 잘 이해하고 사용하면 너무 재밌을 것 같아서 실습을 진행했다.
🔍 과정
- 모델 설명
네이버 리뷰 데이터를 이용하여 문장의 긍정/부정을 가려내는 모델
- 모델 구조 (상단 깃허브 링크 확인)
Embedding -> Attention -> output(1)
- Attention 적용
query와 잘 어울리는 input data를 blending하여 새로운 벡터를 만들어야 한다.
RNN 계열의 encoder를 사용하지 않고, 어텐션 매커니즘만을 적용해보고 싶었다.
하지만, query로 어떤 데이터를 삼아야할지 잘 떠오르지 않았다.
(encoder를 사용했다면 직전 hidden state가 query였을 것)
query를 활용하는 게 중요해보이지만, 나는 모델 자체가 익숙하지 않았다.
따라서 모델 구축하는 연습을 해보기 위해, query 없이 attention score를 계산해서 구현해봤다.- vocabulary 구성
처리를 많이 해줘야 할 한국어 데이터셋이지만, 단순히 공백 단위로 split()만 적용했다.
- 결과
아래는 모델이 잘 분류한 데이터와 잘못 분류한 데이터들이다.

잘 분류한 데이터 
잘못 분류한 데이터
잘 분류한 데이터는 나름 중요해보이는 단어의 attention score가 높게 나타났다. (모델이 판별한 주요 단어)
테스트 데이터의 정확도는 75%정도가 나왔다.
공백 단위로 split하여 단어들이 희소한 분포를 띄어서 학습이 덜 되었을 수도 있고,
위와 같은 반어적인 표현들 때문에 간단한 모델로 학습이 힘들었을 수도 있을 것 같다.
아래는 validation accuracy이다.
validation
attention score를 기준으로 heatmap을 그려보았다.
아래는 모델이 잘 분류한 데이터의 heatmap이다.
이모티콘처럼 사용하는 :)의 attention score가 높게 나타난 것이 인상적이었다!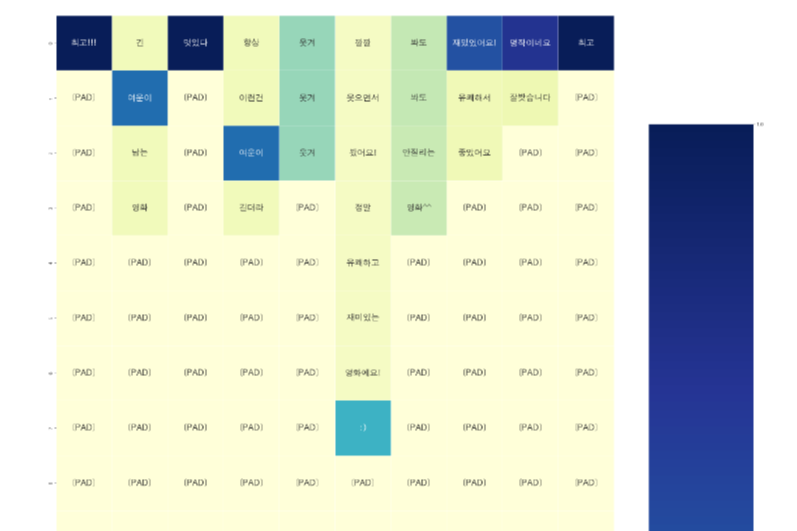
잘 분류한 데이터
아래는 잘못 분류한 데이터이다.
train 데이터에 없던 word를 뜻하는 UNK가 많이 보이는 것을 알 수 있다.
vocabulary를 똑바로 구성하지 못 한 탓인 것 같다.
잘못 분류한 데이터 - 결론
어텐션 매커니즘을 공부하던 중이었지만, 전처리가 중요하다는 것을 다시 한 번 깨닫게 되었다.
모델이 입력의 어떤 부분을 중요하게 판단했는지 점수로 나타낼 수 있다는 것이 놀라운 것 같다.
다음엔 query까지 제대로 포함한 모델을 생각해서 구현해봐야겠다.'NLP' 카테고리의 다른 글
감정분석 (naive bayes classifier, 나이브 베이즈 분류기) (3) 2022.10.02 cost function of Logistic Regression (0) 2022.08.11 Feature Scaling의 효과 (Loss 시각화) 실습 (0) 2022.07.29 Feature scaling의 종류 (0) 2022.07.28 Simple Linear Regression 실습 (0) 2022.07.27 댓글
녕로그
App 개발, 머신러닝을 공부하는 블로그입니다.
